Automate invoice processing using AWS Textract

I am a seasoned IT professional with deep experience in delivering business solutions in a variety of industries. Over the years I have successfully handled all aspects of project lifecycle - planning, product selection, analysis, architecture, design, development, implementation and support.
A routine task that every business must perform is to process invoices. Often, these invoices are received in paper form or as email attachments. Processing these invoices can - a) be tedious, b) consume a lot of time and c) be error-prone. This makes invoice processing a good use case for automation.
Overview of Textract
The primary challenge in processing invoices is extracting the relevant data. This is where Amazon Textract can help. It is a service provided by Amazon Web Services (AWS) that uses advanced Machine Learning (ML) algorithms to automatically extract structured and unstructured data from scanned documents, images, and PDF files. It can detect typed and handwritten text in different types of documents including invoices, financial reports, medical records, tax forms etc. Under the hood, it uses Optical Character Recognition (OCR) technology and pre-trained ML models to understand and interpret the content of documents.
Textract Demo
Here is a quick demo to showcase how Textract can be used to extract relevant information from a scanned invoice.
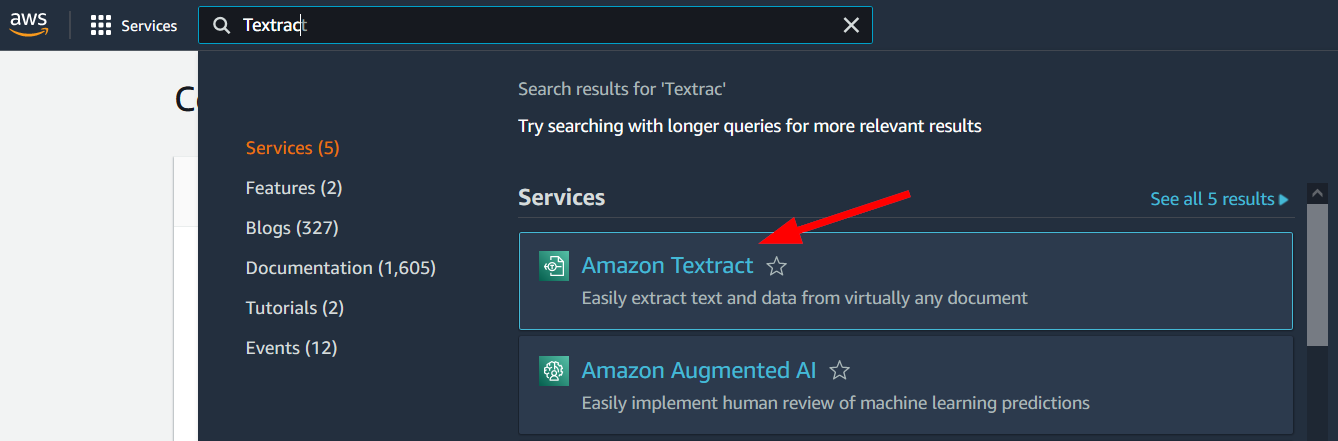
Let's jump to the AWS console and see how it works. Log into your AWS account and search for Textract in AWS console. Click Amazon Textract in the search results.
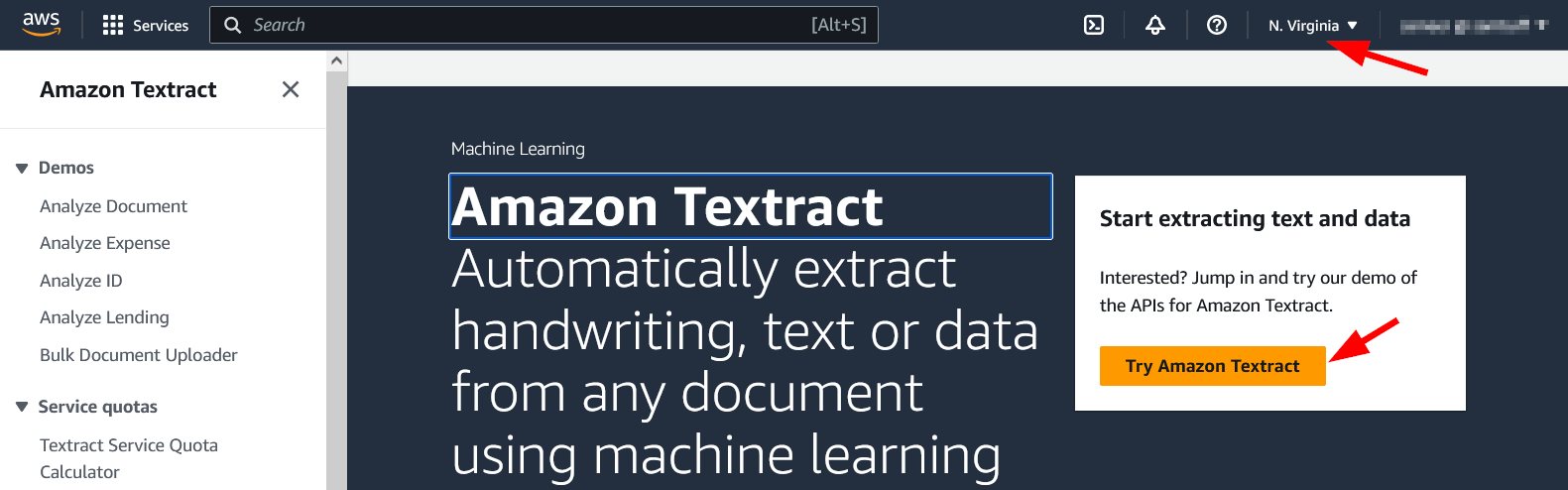
This brings us to the Textract page. For this demo, we will use the US East N. Virginia region.
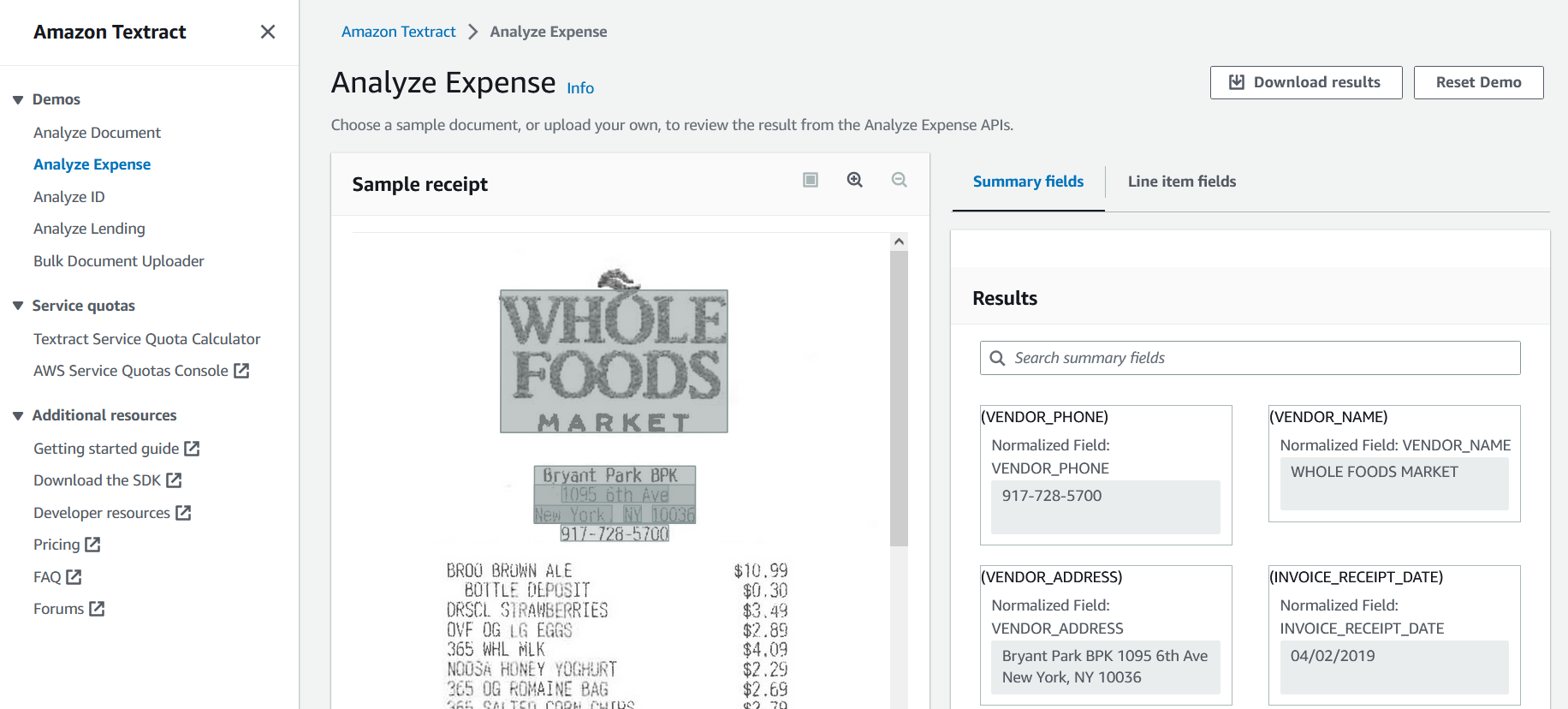
Click on Try Amazon Textract button. This navigates to the Analyze Document screen. Since we want to analyze an invoice, click on the Analyze Expense option in the menu on the left.

By default, this screen shows a sample document and the relevant information extracted by Textract. We can see the image of a Whole Foods receipt on the left and the extracted raw text on the right.
Scroll down and pick the Invoice option. Selecting this option updates the sample to an invoice document and the text extracted from it. We want to use Textract for our sample invoice, so click Choose document to upload it.

We will upload an image from the local drive (download this invoice image).
Textract will take a few seconds to process the invoice once it is uploaded. Soon, we will see our invoice with the extracted text outlined.
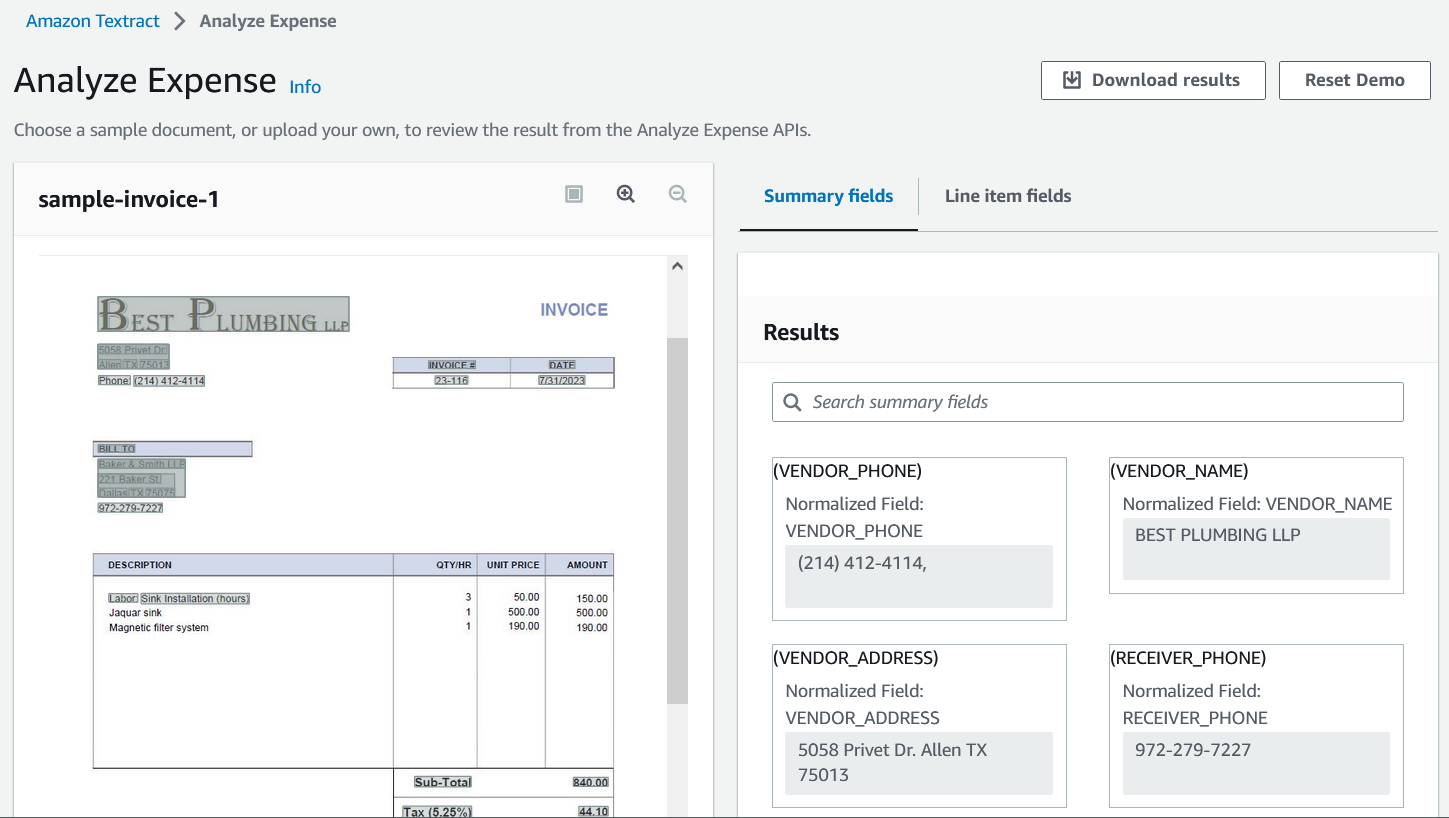
On the right, we can see important summary fields like Vendor Name, Vendor Address, Reciever Name, Receiver Address, Invoice #, Invoice Date etc. Clicking on Line item fields shows the invoice line items.
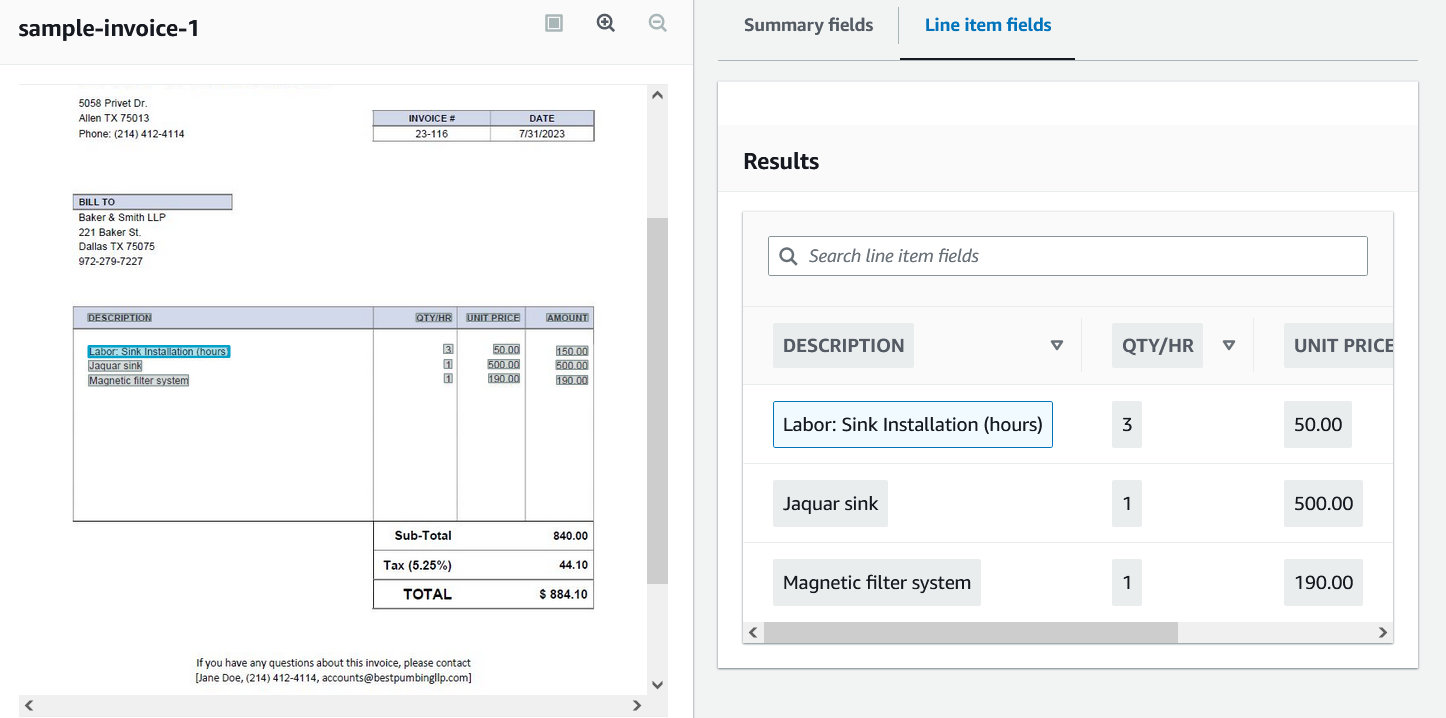
The right panel shows that all the line item details have been correctly extracted. As you can see, Textract can detect and extract tables quite nicely. Another interesting feature is that if you click on any of the text items in Results, it will highlight the portion of the invoice from where the text item was extracted.
Click Download results button to download the information extracted from the invoice as a zip file.
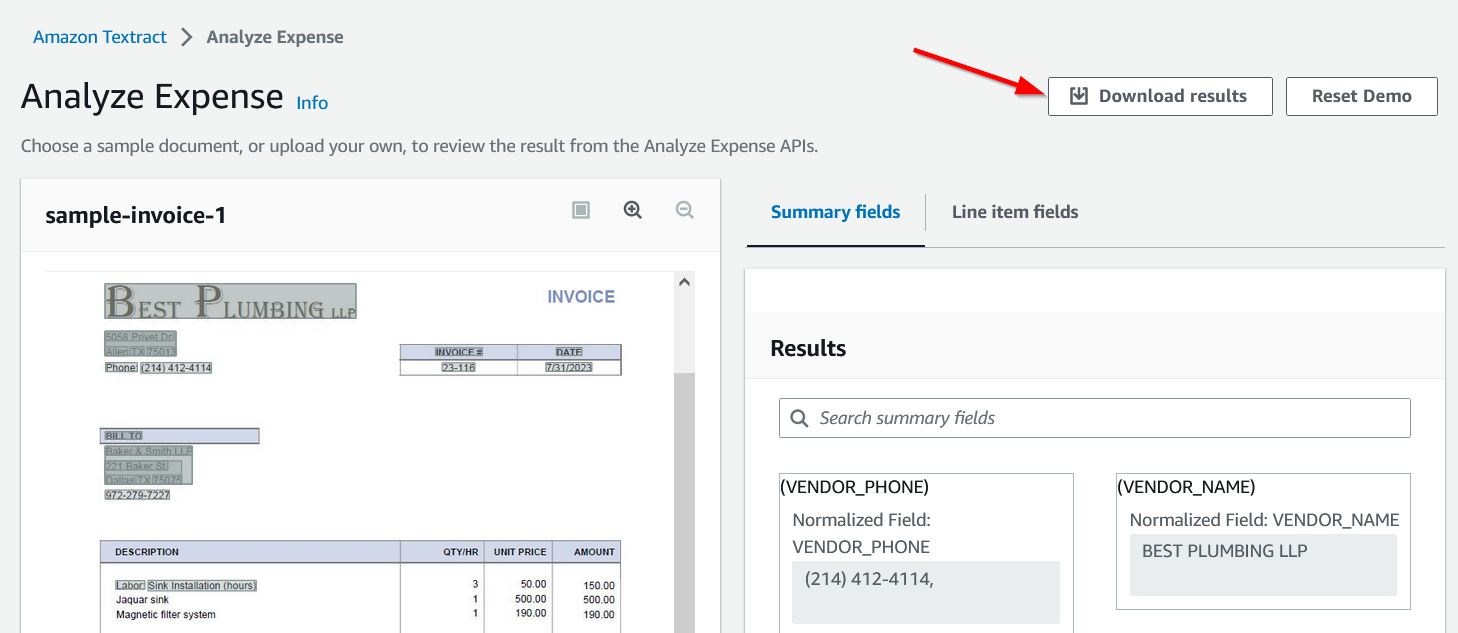
The downloaded zip file has three files- two CSV and one JSON file.
File summaryFields-1.csv contains the extracted summary information such as the Vendor name, address, phone etc.
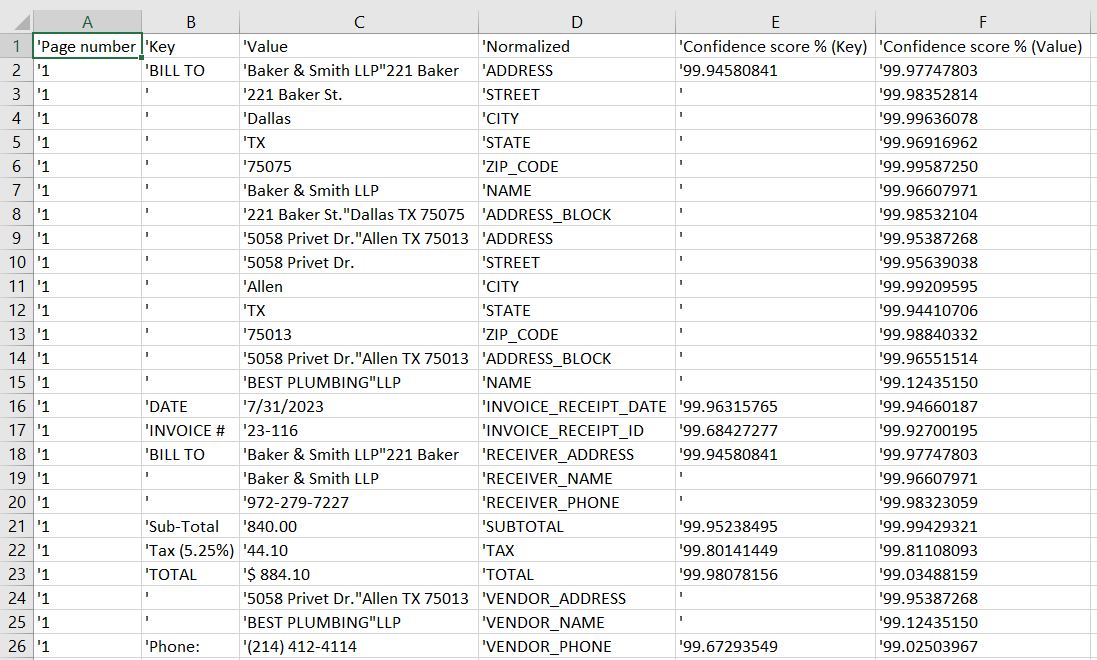
File lineItemFields-1 contains the line item details extracted.

Note that it also shows the confidence scores for extract labels, column titles and values.
File analyzeExpenseResponse.json contains a lot more additional details including geometric information (position and size of extracted text) etc.
Conclusion
We saw in this demo that Amazon Textract goes beyond simple OCR to identify, understand, and extract data from forms and tables. The only information we provided was that the document is an invoice. We did not specify any labels, text or positions to extract. The use of pre-trained ML models makes Textract smart enough to automatically identify the appropriate labels and text relevant to an invoice.
In this article, we saw a quick demo of Textract using the AWS console. Textract provides a wide range of CLI and SDKs for Python, Java, NodeJS etc. In the next article, we will use a Python script to programmatically extract data from the same invoice using Textract SDK.